说到TCP与UDP协议的不同,我们首先会认识到,TCP是面向连接的,或者说面向字节流协议,而UDP是非面向连接的,或者说面向报文协议,因为这种不同造成的对于消息边界的处理的不同,确实常常被忽略。我们首先来梳理一下TCP与UDP协议的不同,然后分析一下两种协议的消息边界不同的根本原因,对于TCP的消息边界问题,常见的有哪些处理方式,最后简要分析一下这些方式的优劣。
TCP与UDP的不同
TCP与UDP的不同,最直接的反映是在协议头部:
1 | { |
1 | { |
我们常见的关于TCP与UDP的不同为以下几个方面:
- TCP消息头部比UDP大,除了源端口和目的端口,数据包长度,校验和字段(共8字节),TCP还包含位序号,确认号,头部长度及众标志位,滑动窗口大小和紧急指针等字段。
- 因为头部的标记位和确认号,TCP有消息确认与重传机制,而UDP没有。
- 2的不同导致TCP是可靠协议,而UDP不是。
- 由于TCP的序列号和确认号,TCP在接收端有序,结合可靠的特性,TCP被认为是面向流的协议,而UDP是面向报文协议。
- TCP有拥塞控制,其实是由于TCP的确认与重传,导致TCP会被UDP报文更多,宏观上看,过量的重传会导致网络环境拥塞而陷入负自循环,为了防止过量重传,需要采用算法来进行控制,避免出现拥塞,拥塞控制算法正是发送端与接受端通过传递TCP头部的窗口大小字段来控制发送端发送报文的速率,进而来影响整个网络的拥堵环境。拥塞控制算法:慢开始与拥塞避免,快重传和快恢复,随机早期检测RED。
- TCP有复杂的握手和挥手过程,而UDP没有。
TCP与UDP所面临的不同消息边界
UDP不存在消息边界问题,一个数据包就是一个消息,我们所说的消息边界,主要是TCP所面临的。
它产生的原因,在发送端和接收端都有。
在发送端,是由于发送端的一些优化算法,比如Nagle算法,为了保证TCP的报文的递送效率,将小的数据单元包合并成大的数据包,而在接收端,TCP协议报按序列号确认,把TCP连接内到达的数据,当作一个数据流,数据流如何拆分成数据单元,TCP却并没法控制。
消息发送方发送如下的字符串:
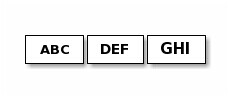
而接收方可能收到如下的字符串:
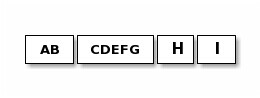
如果没有好的办法能使发送端把字符串的区隔重放到接收端,接收端得到的只是一堆没有意义的数据包。
TCP消息边界问题解决办法
目前使用的解决办法都是从上层协议的角度进行的。
- 固定长度
上层协议确定封装长度,发送端与接收端使用相同的长度进行解包。 - 带固定长度的header标记后续内容长度
上层协议在固定长度的header中,指明后续报文的长度,发送端在封装数据的时候将数据长度写入header中,接收端读出header后,读取指定长度的内容解包为数据。 - 插入分隔符
协议中使用固定字符作为分隔符,来作为数据单元分隔的标记。 - 混合方式
如HTTP头部使用CR LF作为Header数据的分隔,而Header中使用Content-Length指明HTTP的消息体大小。
TCP消息边界问题解决办法的优劣分析
- 固定长度
无法适应数据长度比较随机的环境,小的数据单元会造成报文字段浪费,大的数据单元会被强制拆分。 - 固定长度的Header,标记后续内容长度
需要额外的数据位来传递Header,数据包数据密度比纯数据包低。 - 插入固定分隔符
递送效率比使用头部的方式高,但是需要对分隔符本身做处理,也就是分隔符转义,且在读数据的时候,需要按字节判断,处理速度慢于Header。
我们常见的协议中,也有将2和3策略混合使用的,如HTTP协议中,头部信息是使用CR LF换行符来分隔头部单元的,而头部协议中使用Content—Length来指明HTTP数据段的长度。